Paper review : Deep Gaussian Process for Crop Yield Prediction Based on Remote Sensing Data

setwd(d:/r_data/agdatalab_blog)
Paper review : Deep Gaussian Process for Crop Yield Prediction Based on Remote Sensing Data
Published in : Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence
초록 요약
연구 배경 : 개도국에서의 농업 모니터링은 기근을 예방하고 인도주이적 노력을 지원하는 의미를 가짐. 농업 모니터링의 주요 도전과제는 수확 전에 작물의 생산량을 예측하는 것임
연구 목적 및 방법 : 공개된 위성 영상 데이터를 이용하여 확장가능하고 정확하며 저비용의 작물 생산량 예측 방법의 3 가지 개선점을 소개하는 것임
개선점 1 : 과거에 수작업으로 선별되던 feature를 최신의 대표적인 learning 아이디어로 자동으로 선별하게 함
개선점 2 : 차원 축소에 탁월한 기법인 CNN(Convolutional Neural Network), LSTM(Long-Short Term Memory) 방법을 이용하여 라벨링된 학습 데이터가 부족한 상황에서도 유용한 feature를 학습하게 함
개선점 3 : Gaussian Process 구성 요소를 통합하여 데이터의 시공간 구조를 명시적으로 모델링하고 정확도를 더욱 향상시킴
- 연구 결과 : 미국의 카운티 차원의 콩 수확량 예측에 대한 3 가지 접근 방식을 평가하고 경쟁 기술보다 우수한 것을 확인함
1. Introduction
기존 연구는 조사 데이터와 작물 수확량을 모델링하기 위해 작물 성장과 관련된 다른 변수(예 : 날씨 및 토양 특성)을 주로 사용하나 이는 미국과 같이 양질의 데이터가 풍부한 경우에는 연구가 가능함.
- 미국의 Daymet , Cropland Data Layer는 훌륭한 데이터를 제공함
일반적으로 수확량 예측에서 중요하게 사용되는 날씨, 토양 특성 및 정확한 지표면 데이터는 개발도상국에서는 사용이 어려운데 반해 다중스펙트럼 위성 영상 데이터는 전 세계적으로 사용 가능함. 그러나 데이터가 고차원이라 추출이 어려운 문제는 있음
NASA는 MODIS를 통해 위성 영상 데이터를 무료로 제공함
데이터 활용 예 : 종분포 모델링(Fink, Damoulas, and Dave 2013), 빈곤매핑(Xie et al 2016, Jean et al 2016, Ermon 외 2015), 기후 모델링 (Ristovski 2013), 자연 재해 예방(Boulton, Shotton, Williams, 2016)
본 논문에서는 다음의 차별점을 가짐
최신의 컴퓨터 비전 기법을 이용해 새로운 차원 감소 기술을 사용하여 훈련 데이터의 부족을 극복함. 특히 원본 이미지를 색상을 히스토그램으로 처리하고 평균 필드 근사를 사용하여 다루기 쉽도록 만듬
토양 특성으로 인해 데이터 포인트 사이의 시공간 의존성을 명시적으로 설명하지 못하는 문제를 신경망 레이어에 Gaussian Process 레이어를 통합하여 이러한 한계를 극복함
실험 결과는 미국에서 카운티 수준의 콩 수확량을 예측하는 작업에에서 USDA 전국 수준추정치 대비 RMSE (Root Mean Squared Error) 30% 향상, MAPE (Mean Absolute Percentage Error) 15% 향상되었음
Comment : 미국과 같은 농업 선진국이 아닌 양질의 데이터가 부족한 개발도산국에서 활용 가치가 더 높은 최신의 기법을 적용한 방법을 제안한다는 점에서 주의를 끌고 있다. 서론에서 독자의 호기심을 사로잡아야 한다는 점에서는 간결하게 잘 써진 것 같다.
3. Preliminaries
3.1. Deep Leaning Models
입력층의 값들로 구성된 n차원 벡터 x와 출력층의 값으로 구성된 n’차원 벡터 c는 아래의 n x n’차원의 가중치 W 매트릭스와 n’차원의 바이어스 벡터 b로 표현 가능함
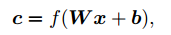
CNN은 주로 Convolutional, Pooling, Fully connected 3종의 Layer로 구성됨. CNN 참고 링크
- Convolutional Layer에서는 2차원의 입력층에서 가중치를 공유하는 방법으로 추정해야 하는 parameter 수를 대폭 줄였으며 ReLU와 같은 비선형 함수를 통과하는 h x w x d차원의 입력 tensor x와 경우에 따라서는 아래 식을 통해서 h’ x w’ x d’차원의 출력 tensor c를 얻게 됨
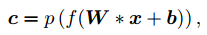
p(.)는 Pooling 함수이고 f(.)는 비선형 함수이며, W는 l x l x d’차원의 가중치 매트릭스로 Convolutional filter로 정의됨. *는 2차원의 convolutional 연산자를 의미함
C(Convolutional) - P(Pooling) - C - P Layer는 다중으로 쌓을 수 있고 Output Layer와는 최종적으로 1층 이상의 Fully connected Layer를 통해 연결됨
LSTM은 연속적인 입력 데이터에서 주로 사용되는 Recursive Neural Network(RNN)의 특수한 타입임
각각의 시간 간격 t에 대해서 hidden state 벡터 ht(직전 단계의 ht-1에 종속됨)를 가지는 것이 특징임
ht-1에서 ht로의 맵핑에서 LSTM cell들로 인코딩이 되고 ht와 출력층인 ot와의 맵핑은 Fully connected layer로 연결되며 모든 시간 단계에 걸쳐 parameter가 공유됨
딥러닝 모델로 주로 소개되는 것은 Convolutional Neural Network(CNN)와 Long-Short Term Memery(LSTM)이다. 딥러닝의 기본인 Deep Neural Network(DNN)는 Fully connected layer로 구성된 feed-forward network인데 첫번째 식으로 신경망 Layer의 Activation Fucntion을 표현하고 두번째 식으로 CNN의 Pooling Layer를 표현한 것은 정말 간결하다.

4. Proposed Approach
4.1. Ploblem Setting
수확 전에 촬영된 위성 영상에 기초하여 대상 지역에 대한 작물(예: 콩)의 평균 수확량을 예측하는 문제를 고려함
Y변수 : 특정 지역의 단위 면적당 평균 산출량
X변수 : 특정 지역의 다중 스펙트럼 이미지(I(1), …, I (T)), I(t) 간격은 8일. 텐서 I(t)는 l × w × d차원(l, w는 수평 및 수직 픽셀 수, d는 픽셀 당 밴드 수)
기타사항 : 농경지에 해당하는 픽셀을 식별하는 일반적인 “작물 마스크”는 전 세계적으로 500m 해상도(DAAC 2015)에서 사용할 수 있음
새로운 접근방법을 소개하면서 모델이 해결하려는 문제를 변수로 간단히 설명하는 것으로 시작한다.
4.2. From Raw Images to Histograms
Raw 이미지 가공은 아래의 이유로 필요함
트레이닝 데이터 D가 희박(10,000개 미만)하므로 심층 모델을 직접 훈련하는 것은 어려움.
Imagenet 등 컴퓨터 비전에서 널리 사용되는 모델은 위성 영상의 다중 스펙트럼 데이터에 부적절
따라서 순열 불변성 가정 하에서 직관에 기반한 차원 감소 기법은 다음과 같이 설계함
평균 산출량이 경작지의 위치를 나타낼 뿐이므로 이미지 픽셀의 위치에 크게 의존하지는 않음. 위치에 대한 일부 의존성이 존재하지만(예: 토양특성, 표고) 계산 편의를 위해 의존성은 고려안함
순열불변성(permutation invariance)이 성립한다고 가정하면, 이미지의 다른 픽셀 유형 (픽셀 카운트)의 개수만이 의미있음. 즉, 고차원 이미지 각 픽셀 값을 히스토그램으로 매핑 할 때 정보 손실이 없음
히스토그램이 256개 픽셀의 9개의 밴드를 고려할 경우 256^9의 경우가 나오기 때문에 무의미해지므로 9개 밴드가 독립적이라고 가정함으로써 암시적으로 mean-field 가정 (Parisi 1988)을 만듦
1만개 데이터도 딥러닝에서는 희박하다고 혹평을 받는다. Raw 이미지 가공이 필요한 이유를 잘 설명하고 있으며 한 이미지 내에서의 픽셀 위치가 큰 의미가 없음을 가정하고 히스토그램으로 변환하는 것이 문제 없다고 한다. 또한 9개 Band가 독립적이라는 가정을 mean-field 이론에서 가져와서 타당성을 높이는데 나는 mean-field 이론을 잘 몰라서 넘어가는 걸로..
4.3. From Histograms to Crop Yield
히스토그램 접근법으로 입력 데이터의 차원을 대폭 줄일 수 있지만 원하는 매핑 (H(1), …, H(T))→y 은 매우 비선형이고 복잡함. Feature를 직접 추출하는 대신 딥러닝 모델을 사용하여 데이터로부터 feature를 자동으로 학습하도록 함
LSTM 아키텍처는 다음과 같음
입력 : 히스토그램 벡터 시퀀스 (H(1), …, H(T))를 사용
모델 구조 : 마지막 LSTM 셀에 Fully connected Layer를 추가하여 그림 1b와 같이 연결함
전처리 : 모델을 맞추기 위해 먼저 각 b × d 차원의 히스토그램 H(t)∈R 를 r(b x d)차원의 벡터 S(t)∈R 로 전개 한 다음 시퀀스 (S (1), …, S(T))를 네트워크에 추가 (T=30)
r이 왜 288인지는 모르겠음Drop out Layer : 오버피팅 방지를 위해 0.75 비율로 추가하여 네트워크를 정규화함
CNN 아키텍처는 다음과 같음
Karpathy et al.(2014)의 순차적 데이터에 대한 CNN 아키텍처에 영감을 받음
전처리 : H(t)는 3 차원 b x T x d 차원의 히스토그램 H ∈ R을 H(1), …, H(T) 형태로 쌓음. H(t)는 H의 2차원에서 t 번째 성분. (Fig 1a)
입력 : 3-D 히스토그램을 사용, Convolution 연산은 “bin”(y축), “time”(x축)차원에 대해 수행
모델 구조 : Fig 1c 참고
Pooling Layer 대체 : 히스토그램의 다른 위치가 다른 물리적 의미를 가지므로 주어진 위치 불변 속성이 필요없는 경우(LeCun, Bengio, Hinton, 2015)로 Pooling Layer 사용 안함 대신 중개 feature 사이즈를 줄이기 위해 stride-2의 Convolutional Layer로 대체함
정규화 : Gradient 흐름을 용이하게하기 위해 일괄 정규화 사용(Ioffe & Szegedy, 2015)
Drop out Layer : 각 Convolutional Layer 다음에 오버 피팅을 방지하기 위해 0.5 비율로 드롭 아웃
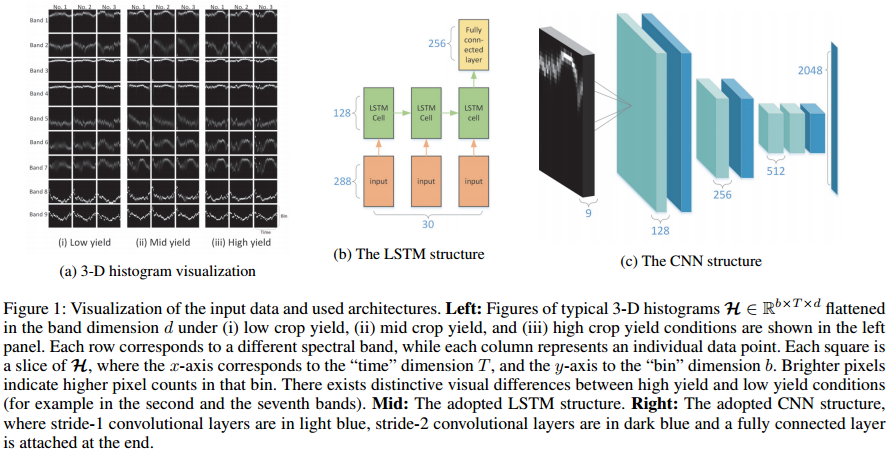
x축은 시간, y축은 히스토그램 bin, z축은 band 종류를 의미하는 3차원으로 표현되는 히스토그램이 LSTM과 CNN의 입력데이터로 어떻게 연결되어서 각 NN이 어떤 구조를 가지고 작물 수확량까지 이어지는지를 잘 설명하고 있다. 파장 값을 의미하는 2차원의 영상 내의 픽셀 값을 1차원 히스토그램 bin으로 맵핑해서는 다시 시간의 흐름을 연결해서 2차원을 만들고 2차원이 9개 Band로 포개질 수 있는3차원 히스토그램을 만든 아이디어는 매우 참신하다. 이 히스토그램은 일반 이미지와 다르기 때문에 Pooling Layer를 쓰지 않는다는 것도 좋은 팁이다.
4.4. Integrating the Spatio-temporal Information: Deep Gaussian Process
입력 데이터가 가진 문제점 중 공간적-시간적 상관성을 고려해야 함
토양 유형, 비료 비율 등 위성 영상에서 밝혀지지 않는 작물 성장 관련 feature들이 존재함
이러한 특징은 특정 위치(예: 토양 유형)에 내재할 수 있으며 시간이 지남에 따라 크게 변하지 않을 수 있으며 공간적/시간적 패턴을 나타낼 수 있음
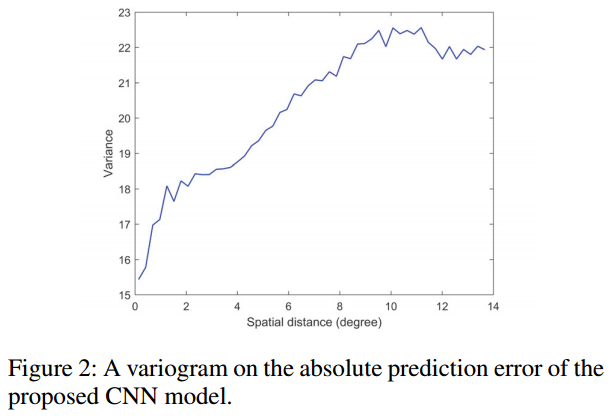
공간적 거리가 가까울수록 예측 오차의 분산이 더 작은 것이 그 증거임 (Fig 2)
해결 방안으로 앞서 설계된 DNN에 Gaussian Process 모델을 통합함으로써 오류를 줄일 수 있음(Hinton, Salakhutdinov, 2008; Wilson et al., 2015).
문제 : 오차는 공간적/시간적으로 서로 상관관계를 가지는데 CNN, LSTM 모델의 입력 데이터는공간적 인접성은 고려되지 않았고 시간은 한 작기 내의 8일 단위의 흐름만 고려되었을 뿐 연도별 상관관계는 고려되지 않았음
해결방안 : Gaussian Process 모델을 CNN, LSTM 모델의 최종 Layer의 입력 feature에 대하여 입력 데이터셋의 시공간 구조와 종속되는 공분산 커널을 가지는 선형 Gaussian Process 모델을 설계함
Detail : x=(I(1), …, I(T), gloc, gyear)로 g=(glog,gyear)를 추가하고 I(t) 세트로부터 추출 된 feature 벡터를 h(x)라고 두고 Gaussian Process 식을 풀어서 수행함. 러닝 방식은 Rasmussen(2006) 참고
이 논문의 백미라 할 수 있는 GP의 적용은 Newwork의 최종 Layer의 입력 Feature에 대하여 적용되는데, 관측 이미지들 간의 공간적(인접성)/시간적(연도별) 상관관계를 고려하여 현재 입력값이 다른 입력값들과의 공분산이 존재함을 가정한다. 이런 가정은 예측치를 도출할 때 지역 인접성과 과거의 트렌드가 고려되어 예측 정확도를 높여준다. 농업 수확량이 연간 집계 데이터인 것을 고려하면 LSTM같은 단기 시퀀스에 강한 구조보다는 GP와 같은 공분산 기반의 방법이 더 적합해 보인다.
5. Experiments
5.1. Data Descripstion
작물선택 : 미국에서 수행된 두 선행 연구(Bolton and Friedl 2013, Johnson 2014)와 비교를 위해 대두(Soybean) 작물 선택
입력 데이터 : 전 세계에서 사용 가능한 MODIS 위성에서 얻은 지표반사율, 육지표면온도, 육지표면유형에 대한 다중 스펙트럼 데이터 포함(DAAC 2015)
시간 설정 : 49 ~ 281일(8일 간격) 동안 연간 30회 수집 데이터 사용
픽셀 히스토그램 계산 : 32개 bin으로 모든 이미지를 이산화하여 b = 32, d = 9 및 T = 30 인 3차원 히스토그램 H=(H(1), …, H(T)) 생성
출력 데이터 : USDA 웹 사이트에 공개된 카운티 수준의 1 에이커당 부셸 단위 연간 평균 콩 수확량 사용. 이는 미국 대두 생산량의 75 % 이상을 차지하고 2003 년부터 2015 년까지의 데이터가 측정된 11개 주를 선택하여 8945개 데이터 셋을 확보함
입력-출력 매칭 : 입력 영상은 카운티 경계에 따라 잘랐으며 non-crop 픽셀은 전세계토지표면데이터(DAAC 2015)을 활용하여 제거
미국은 연구할 데이터가 풍부해서 좋겠다.
5.2. Competing Approachs
예측 성능 비교 : 널리 사용되는 작물 생산량 예측 모델과 비교함. 기준 방법으로는 Ridge 회귀(Bolton and Friedl 2013), Decision Tree(Johnson 2014), 256개 노드의 Hidden Layer 3개의 DNN(Kuwata, Shibasaki 2015)와 비교하였음
입력 데이터 : 비교 모델들은 대상 지역에 대한 T=30 기간동안의 평균 NDVI 값 시퀀스를 사용하였음. 전통적으로 사용되어온 정밀한 픽셀 마스크(예: 대두 마스크)를 이용하여 입력 이미지에서 관련성이없는 픽셀을 제거하였음
특이사항 : 비교모델에서는 기상 데이터를 입력 변수로 사용하지만 비교 분석을 위해 제외하고 실험 조건과 동일하게 맞춤. 비교 모델의 Hyperparameter는 교차유효성 검사를 통해 최적화함
연구 모델에서도 기상 데이터를 쓰면 어떤 차이가 날지 궁금하다.
5.3. Results
Table 1은 카운티 차원 예측 RMSE(Root Mean Square Error)로 다음과 같은 과정으로 계산됨
트레이닝 중 무작위 초기화 및 중도탈락을 고려하여 2회 이상 추출한 평균으로 처리함
전년도의 데이터에 대해 트레이닝한 모델로 차년도 예측
학습률 및 중지 기준은 유효성 검증세트(10 %)를 통해 조정됨
결과는 CNN과 LSTM이 경쟁 방식을 훨씬 능가하는 것으로 나타남. GP 구성요소를 추가하여 각 예측 모델은 최상의 경쟁 방식에서 RMSE를 30 % 감소시킴.
GP가 공간상관 오차를 줄일 수 있음을 보여주기 위해 Fig 3의 2014년 CNN 모델의 예측 오차를 그려보면 GP 적용 전은 오차가 공간적으로 상관관계를 가짐(Where 적색은 과소예측, 청색은 과대 예측). 반면 GP 구성요소를 추가하면 상관관계가 감소하는데 이는 직관적으로 오차가 위성 영상에서 관찰할 수 없는 속성(예: 토양특성 등)에 기인한 것인데 GP 파트가 과거의 훈련 데이터로부터 이러한 패턴을 학습하고 효과적으로 수정한 것으로 설명 가능
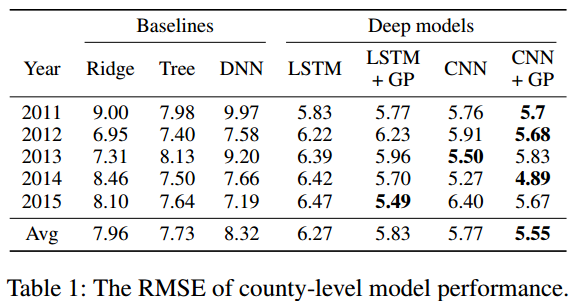
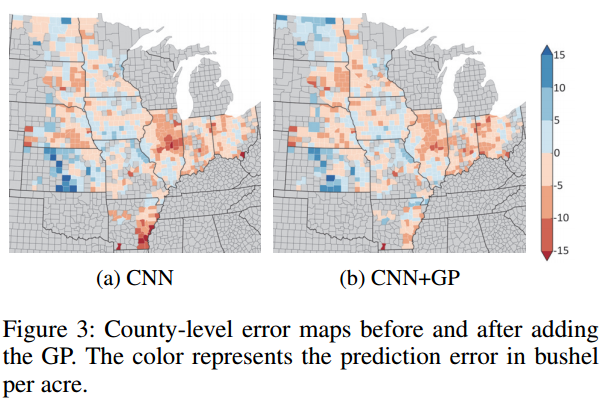
일단 히스토그램화한 데이터에 CNN, LSTM을 적용한 방법에서 압도적인 향상이 돋보인다. GP의 적용은 그에 비하면 RMSE 수치만 봤을 땐 살짝 미흡한 느낌도 있으나 Fig 3을 통해서 예측 오차의 편차를 줄이는 효과를 보여줌으로써 아쉬움을 잠재운다.
5.4. Real-Time Prediction throughout the Year
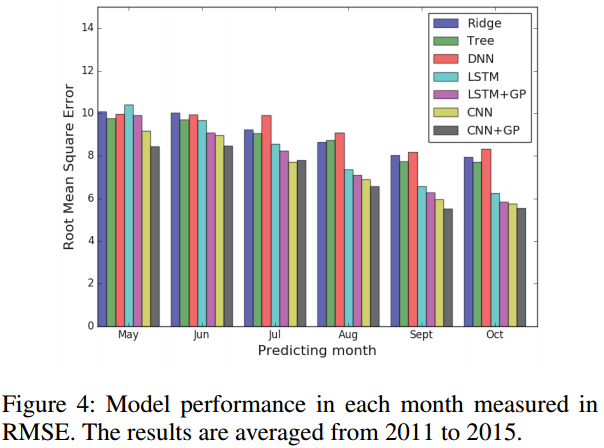
미국에서는 5~6 월에 대두를 심고 10~11 월에 수확함. 재배 초기 생산량 예측을 잘하는 것이 중요하므로 이를 위해 t < T 인 입력 (I (1), …, I (t))의 하위 시퀀스에서 모델을 학습하고 테스트함(Fig 4). 매월 온라인으로 수확량을 예측하려고 시도했을 때의 성능은 식물 성장에 대한 충분한 정보가 아직 없기 때문에 초기에는 모든 모델의 성능이 열악하나 6~9월로 올수록 모든 모델이 향상되면서 비교모델 대비 연구 모델의 격차가 점점 커짐
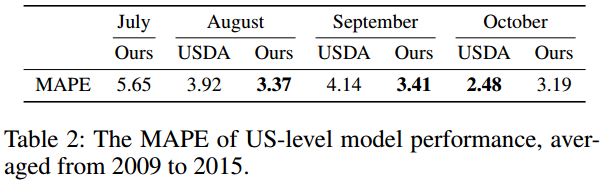
카운티 평균 수확량 예측치를 다시 평균한 예측치의 MAPE(Mean Absolute Percentage Error) 비교에서 USDA 추정치 대비 8, 9월에 평균 15 % 예측성능이 좋았는데 USDA가 서베이 기반인 것을 생각해보면 연구 모델의 방법이 훨씬 싸고 정확함
이 논문의 장점은 성능 개선 효과를 다각도로 보여준다는 것이다. 2~6 개월 후 중장기 예측에 대한 결과도 비교하는데 이는 연구자가 현업에서 중장기 예측이 중요하다는 감각을 가지고 있는 점을 시사한다.
5.5. Understanding Feature Importance
Feature 중요도 비교는 Breiman(2001)에서 사용된 Random Forest에 의한 Permutation 테스트를 적용함.
다른 Feature들을 변경하지 않고 특정 Feature의 값을 전체 데이터에 대해 무작위로 치환하는 효과를 고려함
3-D 히스토그램 입력의 경우 나머지 데이터는 고정 된 상태에서 모든 데이터에 걸쳐 히스토그램 조각을 Shuffling하여 시간 및 밴드 차원에 따라 개별적으로 바꿈(Permutation함)
혼합된 데이터에 대해 훈련 모델의 2011 ~ 2015년까지의 Band 차이에 의한 평균 성능 비교는 다음과 같음(Fig 5)
전통적으로 근적외선 대역인 Band 2는 작물성장의 핵심요소로 사용됨(Quarmby et al., 1993). Band 2의 중요도는 적당히 높은 수준임. 성장 관련 Band 7은 단파적외선 대역으로 전통적인 접근법에 무시되던 대역이나 중요성이 확인됨
육지 표면 온도 관련 Band 8, 9의 영향은 이전 연구(Johnson 2014)에서도 확인됨
작물 성장의 단계별 Band별 중요성이 다름. 성장 관련 Band 2, 7은 재배 종반에 더 높은 상대적 중요도를 보였고, 온도 관련 Band 8, 9는 재배 초반에 더 중요했음.
시간 차이에 의한 평균 성능 비교는 다음과 같음(Fig 6)
설문 조사에 따르면 대두는 일반적으로 110 ~ 190일차에 정식이 이루어지고 수확은 보통 250일차 이후에 시작됨(USDA 2010).
Fig 6의 추세는 가장 유용한 데이터가 재배 기간 (110 ~ 250일차)에 수집이 되고, 수확 직전(약 240 일차)에 정점에 이르는 것을 보여줌
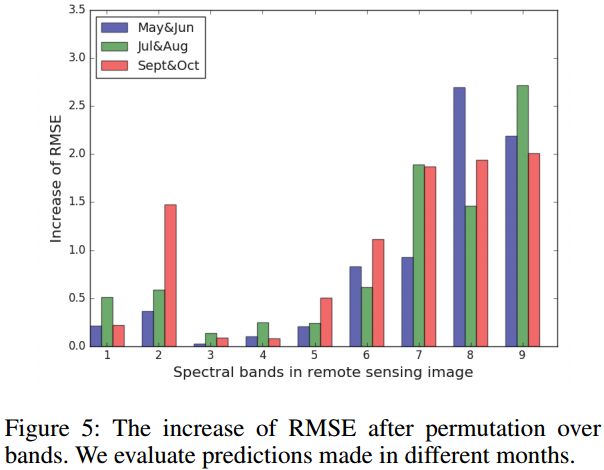
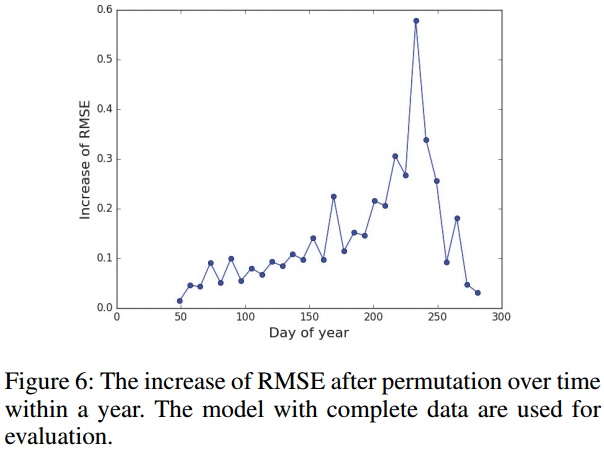
이 파트 또한 매우 참신하다. 입력 데이터의 특정 파트를 랜덤으로 섞은 후 예측치를 뽑고 그 오차의 차이를 비교한다는 것이 어쩌면 작위적으로 보일 수 있으나 레퍼런스도 있는만큼 과학적인 방법이라는 것이다. 9개의 Band별 중요도 비교, 1년 중 어느 시점의 데이터가 더 중요한지의 비교라는 설정도 실무적으로 매우 유용하게 느껴진다.
6. Conclusion
이 논문은 위성 영상을 이용한 작물 수확량 예측의 딥러닝 프레임워크를 제시함
연중 실시간 예측이 가능하며, 전 세계적으로 적용 할 수 있어서 현장 조사가 어려운 개발도상국에서 요긴하게 사용될 수 있음
작물 수확량 예측에 최신의 머신러닝 아이디어를 적용하였고, 기존의 수작업에 의한 Feature가 아닌 원시 데이터에서 훨씬 더 효과적인 Feature를 성공적으로 학습하였음
히스토그램을 기반으로하는 차원 감소 접근법을 제안하고, 공간 상관 오류를 성공적으로 제거하는 Deep Gaussian Process 프레임워크를 제시하였음
이와 같은 논문의 기여는 원격 센싱 및 계산 지속성 분야의 다른 어플리케이션에 영감을 줄 수 있음
총평 : 최신의 기법들을 종합하여 결론을 이끌어내는 과정이 논리적이고 설득력 있다. 결과에 대한 다양한 비교에서 실무적인 감각이 뛰어나다는 느낌이 든다. 이 논문을 보고 위성 영상 기반 인덱스가 농업분야에서 상당히 많이 연구되고 있음을 알게 되었다. 그에 반에 국내에서는 유사한 연구가 거의 안되고 있는 것을 생각하면 답답하다. 부러운 점은 최고 명문인 스탠포드 컴공과 친구가 이런 연구를 한다는 것이다. 미국에서 농업이 메이저 산업이기 때문일까? 아니면 농업 분야에 훌륭한 데이터가 많기 때문일까? 우리나라 농업 연구 관련 정책당국은 한번 생각해보길 바란다.
