스마트팜 데이터의 이해 (2/3)
스마트팜 데이터 요약 : 분단위 측정치와 시간단위 평균치
지난 Post에서 분단위 데이터 dat을 시간단위 데이터로 요약하여 새로운 데이터 dat_hour를 만들었을 때의 저장용량과 다운로드 속도 측면에서의 이점을 설명하였다. 이점이 있다면 그에 반하는 역효과도 분명 발생하게 되는데 1/60배로 데이터를 축약했다면 그만큼의 정보손실이 발생한다.
온실 내부평균온도에 대한 분단위 데이터와 시간단위 데이터의 그래프를 비교해보면 그 영향을 눈으로 확인할 수 있다. X축은 0시~24시까지의 시간, Y축은 내부평균온도(EVTP)로 설정하였다. 임의의 하루를 선택하기 위해 dplyr패키지의 filter() 함수를 사용하였고, ggplot2패키지로 그린 2개의 그래프는 gridExtra패키지의 grid.arrage() 함수로 2 x 1 격자로 배치하였다.
library(dplyr); library(ggplot2); library(gridExtra); library(knitr); library(kableExtra)gg1 <- dat %>% filter(date=='2015-04-19') %>%
ggplot() + geom_line(aes(x=hour+minute/60, y=EVTP), color='red', size = 0.8, alpha = 0.8)
gg2 <- dat_hour %>% filter(date=='2015-04-19') %>%
ggplot() + geom_line(aes(x=hour, y=EVTP), color='blue', size = 0.8, alpha = 0.8)
grid.arrange(gg1, gg2, ncol=1, nrow=2)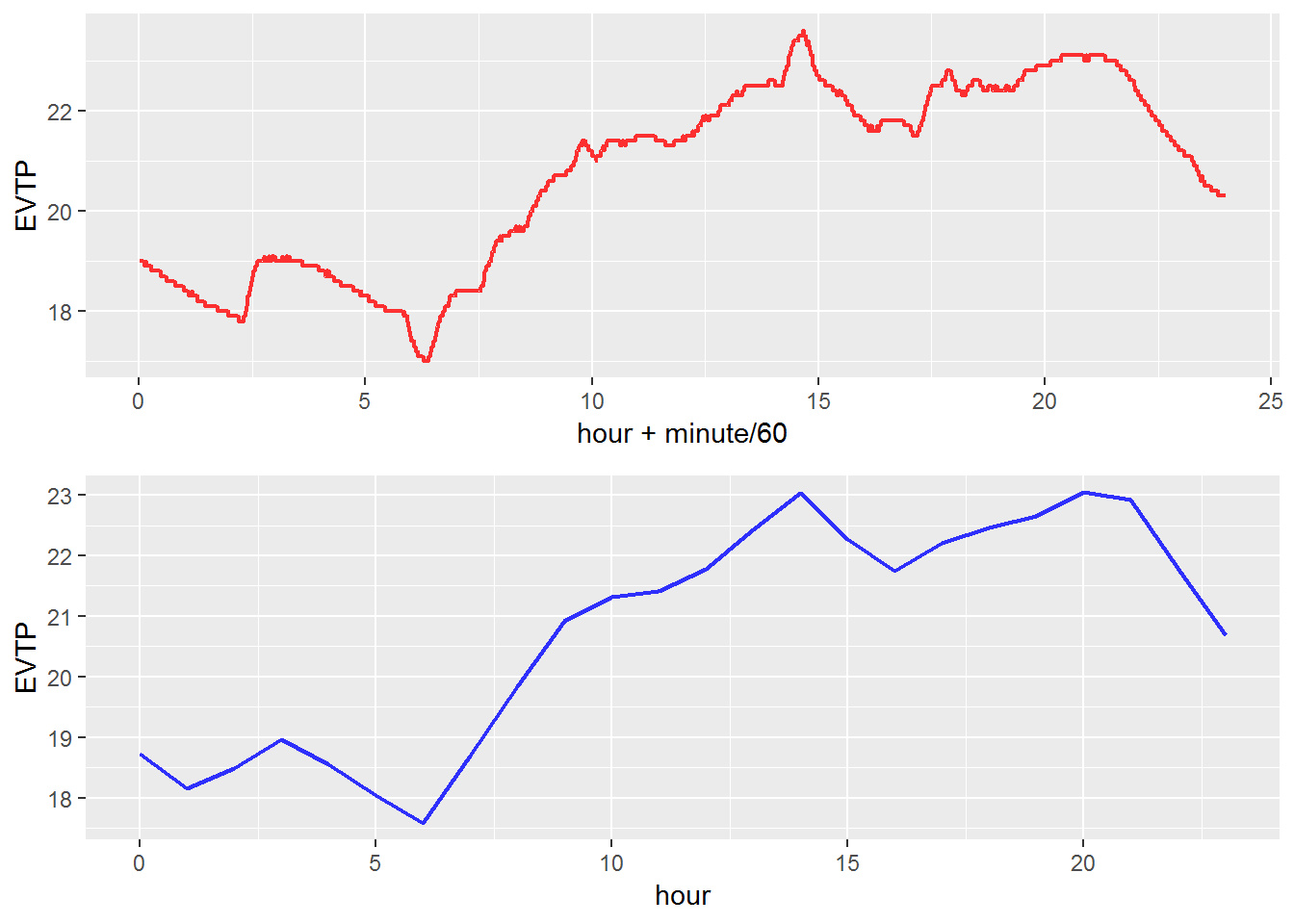
2015년 4월 19일 하루동안 측정된 데이터를 표현해보니 1440개로 뿌려지는 분단위 데이터는 촘촘하게 그려지는 반면 24개로 뿌려지는 시간단위 데이터는 성긴 느낌이다. 분단위 데이터가 좀더 실제 온실 내부온도의 추세를 현실적으로 표현했다면, 시간단위 데이터는 군더더기 없이 시간변화에 따른 트렌드를 더 명확하게 표현한다. 데이터 크기는 크지만 보다 디테일한 분석이 필요할 때는 분단위 데이터를 쓰면 될 것이고, 데이터의 크기가 작아야 하는 상황이거나 트렌드 파악만 필요하다면 시간단위 데이터를 쓰면 되는 것이다.
이번에는 분단위 데이터와 시간단위 데이터를 하나의 동일한 X, Y 차원에 그려보았다. 서로 다른 데이터를 하나의 공간에 그리기 위해서는 ggplot 객체에 서로 다른 데이터를 표현하는 두 개의 ‘geom_line’ 레이어를 까는 방법으로 표현할 수 있다. 내부평균습도(EVHM), 일사량(INS), 이산화탄소농도(CO2), 풍속(WDS) 네 가지 환경 요소를 각각의 그래프로 그려서 gg1 ~ gg4에 저장한 후 grid.arrange()로 2 x 2 격자로 그려보자.
dat_f1 <- dat %>% filter(date=='2015-04-19')
dat_f2 <- dat_hour %>% filter(date=='2015-04-19')
gg1 <- ggplot() +
geom_line(data=dat_f1,aes(x=hour+minute/60, y=EVHM), color='red', size = 0.8, alpha = 0.5) +
geom_line(data=dat_f2,aes(x=hour, y=EVHM), color='blue', size = 0.8, alpha = 0.8)
gg2 <- ggplot() +
geom_line(data=dat_f1,aes(x=hour+minute/60, y=INS), color='red', size = 0.8, alpha = 0.5) +
geom_line(data=dat_f2,aes(x=hour, y=INS), color='blue', size = 0.8, alpha = 0.8)
gg3 <- ggplot() +
geom_line(data=dat_f1,aes(x=hour+minute/60, y=CO2), color='red', size = 0.8, alpha = 0.5) +
geom_line(data=dat_f2,aes(x=hour, y=CO2), color='blue', size = 0.8, alpha = 0.8)
gg4 <- ggplot() +
geom_line(data=dat_f1,aes(x=hour+minute/60, y=WDS), color='red', size = 0.8, alpha = 0.5) +
geom_line(data=dat_f2,aes(x=hour, y=WDS), color='blue', size = 0.8, alpha = 0.8)
grid.arrange(gg1, gg2, gg3, gg4, ncol=2, nrow=2)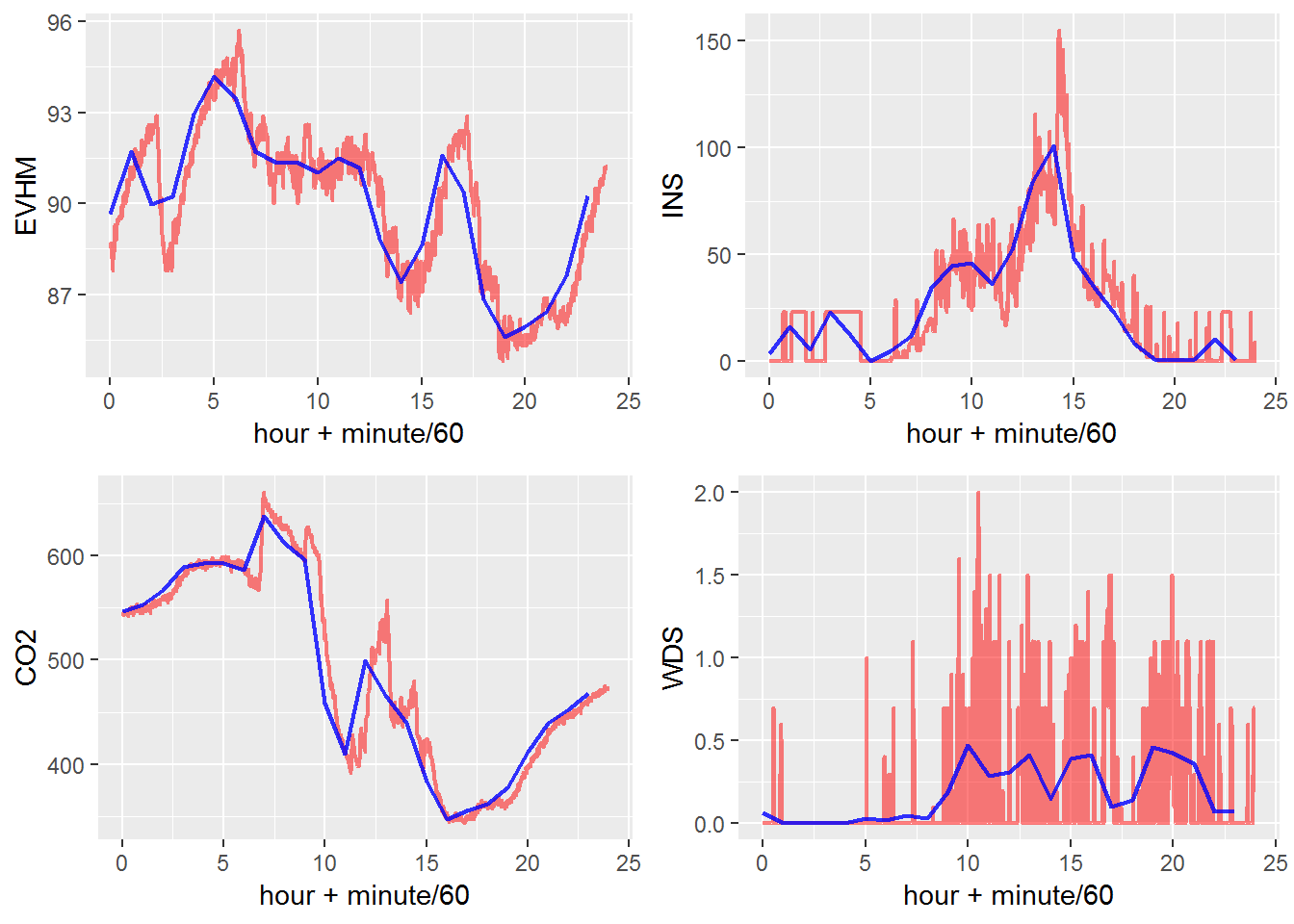
습도, 일사량, CO2는 파란색의 시간단위 그래프로 표현할 경우 노이즈처럼 보이는 분단위 데이터의 변동성을 표현하지는 못하지만 트렌드는 잘 보여준다. 반면 풍속 그래프는 시간단위 그래프가 트렌드를 보여주지만 분단위 데이터의 변동성이 매우 크기 때문에 오히려 분단위 데이터로 해석을 하는 것이 적절해 보인다. 일사량 그래프에서도 14~15시의 최대 일사량의 피크점은 시간단위 데이터는 포착하지 못하고 있고, CO2 그래프에서도 12~13의 550ppm까지 상승하는 패턴을 시간단위 데이터에서는 표현하지 못하는 것을 확인할 수 있다. 이처럼 시간단위 데이터로 표현했을 때 놓치게 되는 분단위 데이터의 특정 패턴들이 중요한 의미를 가지는지를 평가하고 어떤 형태로 데이터를 보여주고 해석할 것인지는 현장 지식을 가진 사용자와 분석가의 고민을 필요로 한다.
스마트팜 데이터 요약 : 평균, 표준편차, 최대, 최소
데이터의 요약에서 많이 사용되는 통계치는 평균, 표준편차, 최대값, 최소값 4가지이다. 2015년 1년간의 온실 내부온도 측정치 525,081개를 이용하여 1 ~ 12월까지의 월별 평균, 표준편차, 최대값, 최소값을 구하는 코드는 다음과 같다. dplyr의 group_by() 함수를 이용해서 month 변수가 가지고 있는 요소들(1 ~ 12)에 해당하는 경우를 그룹핑하고 그 그룹 내에서 summarize() 함수를 이용하여 요약 통계값을 구한다. 평균 mean(), 표준편차 sd(), 최대값 max(), 최소값 min()을 구하는 함수를 사용하여 TP_avg, TP_sd, TP_max,TP_min의 변수명으로 통계치를 산출했다. 함수 내부의 na.rm = T은 통계값 계산에서 결측치NA가 존재할 경우는 제거하고 통계치를 계산하라는 옵션이다. OTP_avg는 월별 실내온도를 추세와 비교하기 위해 외부온도 평균값을 추가한 것이다.
dat_month <- dat %>% group_by(month) %>% summarize(OTP_avg=round(mean(OTP,na.rm=T),2),TP_avg=round(mean(EVTP,na.rm=T),2),TP_sd=round(sd(EVTP,na.rm=T),2),TP_max=max(EVTP,na.rm=T),TP_min=min(EVTP,na.rm=T))| month | OTP_avg | TP_avg | TP_sd | TP_max | TP_min |
|---|---|---|---|---|---|
| 1 | 2.72 | 19.56 | 3.97 | 33.3 | 14.2 |
| 2 | 3.84 | 19.85 | 4.97 | 35.7 | 13.7 |
| 3 | 8.21 | 21.59 | 5.60 | 38.0 | 13.3 |
| 4 | 14.07 | 21.11 | 4.09 | 33.8 | 14.7 |
| 5 | 19.34 | 23.34 | 5.93 | 36.4 | 12.6 |
| 6 | 21.76 | 23.64 | 4.65 | 36.1 | 14.6 |
| 7 | 25.13 | 27.99 | 5.91 | 46.3 | 15.6 |
| 8 | 25.86 | 28.75 | 5.45 | 44.0 | 19.0 |
| 9 | 21.51 | 23.81 | 4.67 | 36.2 | 15.2 |
| 10 | 16.34 | 21.53 | 3.86 | 32.2 | 13.4 |
| 11 | 12.26 | 19.44 | 3.35 | 30.6 | 12.8 |
| 12 | 5.97 | 17.40 | 3.38 | 28.3 | 12.6 |
요약된 테이블을 보면 온실 내부온도 평균값은 여름철이는 높아지고 겨울철에는 낮아진다. 표준편차는 3,5,7,8월이 높게 나타났다. 최대값은 여를철에는 높고 겨울철에는 낮아지지만 3월에는 특이하게 4~6월보다 높다. 3월 평균온도 역시 4월보다 높은 것으로 보아 3월에는 온실 내부 온도를 높이기 위해 가온(보일러나 열풍기로 온실을 내부 온도를 높이는 것)을 했을 가능성이 있다. 외부온도의 패턴을 보면 3월이 8.21도 4월이 14.07도이기 때문에 3월에 가온을 한 것이 확실시 된다. 3월에 가온을 했던 이유가 파프리카 출하 시기를 앞당기기 위해서였는지, 생육주기에서 온도가 높아야 하는 시기였는지는 환경데이터만으로는 확인이 어렵지만 특이한 패턴을 해석하는 과정에서 추측해보고 실제로 가온 활동이 있었는지 현장에서 확인을 할 수 있다면 “파프리카의 경우 3월에 OO때문에 가온”하는 경우가 있다는 유용한 지식을 추가로 축적할 수 있을 것이다.
이와 같이 평균, 표준편차, 최대값, 최소값이라는 기본적인 통계치만으로도 데이터로부터 의미있는 해석을 이끌어낼 수 있다. 간혹 고급 통계분석을 하는 연구자들이 기술통계라고 불리는 기본적인 통계치를 뽑고 패턴을 확인하는 과정을 소흘히 하여 중요한 정보를 놓치는 경우가 있는데, 기본적인 통계치라는 것은 기본중에 기본이 되는 것이지 기초적인 것이니 가벼이 여겨도 되는 것은 절대 아니라는 점은 명심하자.
