도매시장 데이터 가공과 시각화 - 배추(1/2)
농림축산식품 공공데이터 포털에서 제공되고 있는 도매시장 경락 데이터는 전국 도매시장의 모든 거래의 내용이 거래 건수 단위로 기록이 되어있다 참고. 배추의 경우 월 평균 2만2천 건 이상의 거래가 기록되고 있는데 이 방대한 raw 데이터를 어떻게 보여주는 것이 raw 데이터가 가지고 있는 여러 정보들을 효과적으로 전달할 수 있을까? 정해진 답은 없지만 한가지 확실한 것은 표와 그래프라는 틀에 넣었을 때 우리는 데이터의 의미를 보다 편하게 인지할 수 있다는 것이다.
library(dplyr); library(tidyr); library(ggplot2); library(ggthemes); library(knitr); library(kableExtra); library(formattable); library(plotly)필요한 패키지를 불러들인 후 분석에 사용될 2015년 이후의 배추 품목 raw 데이터를 읽어온다. raw 데이터는 AgData Lab AWS S3 저장소에서 다운받을 수 있다.
dat <- read.csv('cabbage_15-180614.csv')필요한 변수를 생성하는 코드이다. date 변수에서 연(year), 월(month), 일(day), 주차(week), 요일(wday) 변수를 생성하고 year와 month변수를 붙여서 ym, year와 week를 붙여서 yw 변수를 생성한다. year 뒤의 변수 값이 1자리수인 경우는 0이 앞에 붙어서 전체 값의 길이가 변하지 않도록 하였다. 거래중량(weight) 변수는 단위에 맞게 kg으로 환산한 후 거래개수(qty)를 곱하였고, 거래액(sales_amt) 변수는 거래가격(price)에 거래개수를 곱하여 생성하였다. “광역도 시군구” 형태의 문자열인 산지(sanji) 변수는 광역도 변수인 sanji_wide, 시군구 변수인 sanji_city 변수로 파생시켰다. sanji_wide2 변수는 광역도 단위에서 비중이 매우 낮은 세종특별자치시를 충청남도로 포함시키도록 만든 광역도 변수이다. unit_merg 변수는 거래단위량(prut), 단위(unit), 포장단위(package) 변수를 붙여서 만든 실제 거래 단위를 의미하는 변수이다. aucCodeName 변수는 경매와 정가수의인 케이스만 필터링 하였고 마지막 두 줄의 filter() 함수는 도매시장 경락 데이터의 이해 - 배추(1/3) (2/3) post에서 배추 품목의 동질성을 가지는 품종 범위를 어떻게 선정하였고 이상치 데이터는 어떻게 제거하였는지 확인할 수 있다.
dat <- dat %>% mutate(year = as.numeric(substr(date,1,4)),
month = as.numeric(substr(date,5,6)),
day = as.numeric(substr(date,7,8)),
week = as.numeric(format(as.Date(as.character(date),format= "%Y%m%d"),"%W"))+1,
wday = weekdays(as.Date(as.character(date),format="%Y%m%d")))
dat <- dat %>% mutate(ym = ifelse(month <10, paste(year,'0',month,sep=''),paste(year,month,sep='')),
yw = ifelse(week <10, paste(year,'0',week,sep=''),paste(year,week,sep='')),
p_month = ifelse(day<=10,1,ifelse(day>=21,3,2)),
ymp = paste(ym,p_month,sep=''))
dat <- dat %>% mutate(weight = ifelse(unit=='ton',prut*qty*1000,ifelse(unit=='g',prut*qty*0.001,prut*qty)),
sales_amt = price*qty,
price_per_kg = round(sales_amt/weight,2))
dat <- dat %>% separate(sanji,into=c('sanji_wide','sanji_city'),sep=" ",remove=F)
dat <- dat %>% mutate(sanji_wide2 = ifelse(sanji_wide=='세종특별자치시','충청남도',sanji_wide))
dat <- dat %>% mutate(unit_merg=paste(round(prut,0),unit,package,sep=''))
dat <- dat %>% filter(aucCodeName%in%c('정가수의','경매'))
dat <- dat %>% filter(!((unit=='g' & prut<100) | (unit=='kg' & prut<0.1)) & price_per_kg <= 10000)
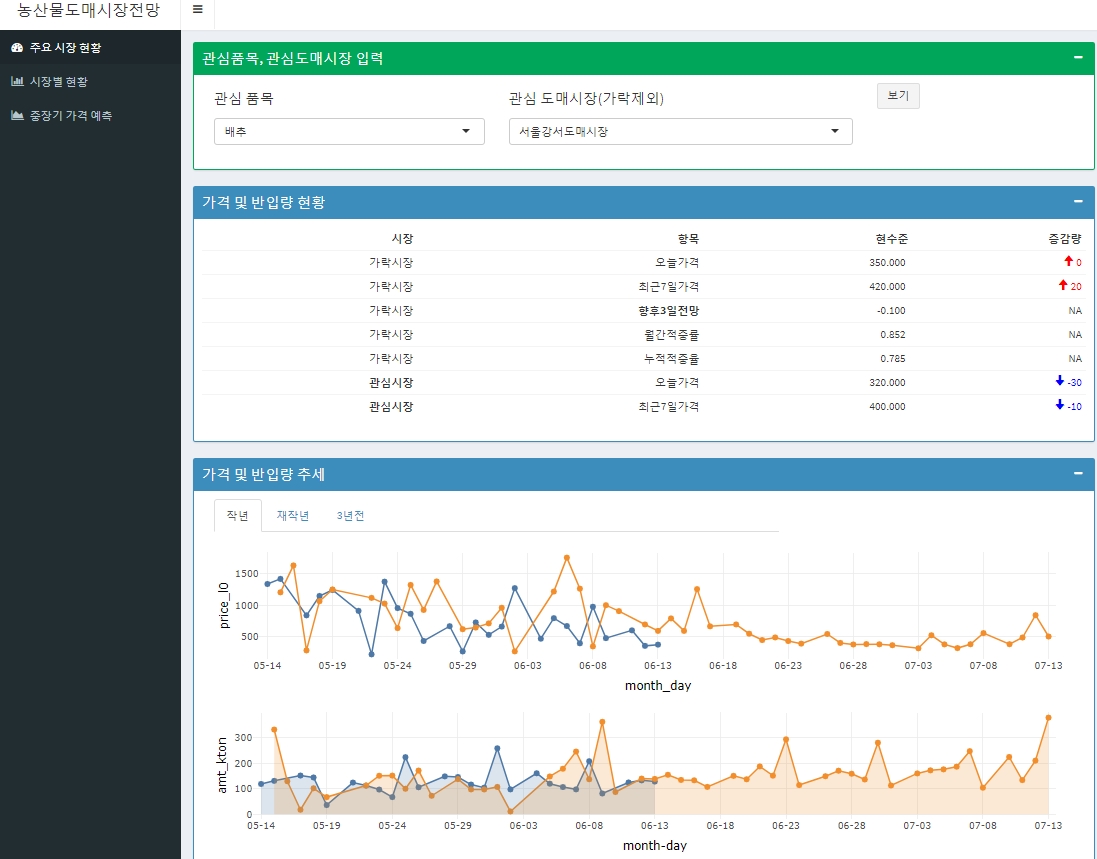
dat <- dat %>% filter(spename %in% c('고냉지','김장(가을)배추','봄배추','여름배추','월동배추','기타'))첫 번째 시각화로 가격 및 반입량 현황 기능으로 오늘의 가격을 최근 7일 평균 가격과 비교할 수 있도록 보여주고 향후 3일 전망 예측치와 예측 모델의 월간/누적 적중율을 보여주는 테이블을 만들어 보자. (진행중)
detach("package:plotly", unload=TRUE)
tab_dash_GR <- data.frame(variable=c("오늘가격", "최근7일가격", "향후3일전망",'월간적중률','누적적중율'),
value_present=c(350,420,-0.1,0.852,0.785),
value_gap= c(0,20,NA,NA,NA))
tab_dash_mkt <- data.frame(variable=c("오늘가격", "최근7일가격"),
value_present=c(320,400),
value_gap= c(-30,-10))
tab_dash <- rbind(tab_dash_GR,tab_dash_mkt)
tab_dash <- rbind(data.frame(market='서울가락도매시장',tab_dash_GR), data.frame(market='관심 도매시장',tab_dash_mkt))
formattable(tab_dash, list( market=formatter("span",style = x ~ ifelse(x == "관심 도매시장", style(font.weight = "bold"), NA)),
variable=formatter("span", style = x ~ ifelse(x == "향후3일전망", style(font.weight = "bold"), NA)),
value_present = color_tile("orange","white"),
value_gap = formatter("span", style = x ~ style(color = ifelse(x < 0 , "blue", "red")),
x ~ icontext(ifelse(x < 0, "arrow-down", "arrow-up"), x))
))| market | variable | value_present | value_gap |
|---|---|---|---|
| 서울가락도매시장 | 오늘가격 | 350.000 | 0 |
| 서울가락도매시장 | 최근7일가격 | 420.000 | 20 |
| 서울가락도매시장 | 향후3일전망 | -0.100 | NA |
| 서울가락도매시장 | 월간적중률 | 0.852 | NA |
| 서울가락도매시장 | 누적적중율 | 0.785 | NA |
| 관심 도매시장 | 오늘가격 | 320.000 | -30 |
| 관심 도매시장 | 최근7일가격 | 400.000 | -10 |
두 번째 시각화는 가락시장의 가격 및 반입량 추세를 현시점 대비 30일 전부터 30일 후까지의 가격(반입량)을 작년과 비교, 재작년과 비교, 3년전과 비교하는 것이다. 현재 시점의 날짜는 date0에 YYYYMMDD``(%Y%m%d)의 숫자 형태로 지정하고 1년전, 2년전, 3년전의 같은 날짜는 10000, 20000, 30000을 빼서 만들어주었다. dat_SO_GR 데이터는 raw 데이터에서 가락시장 케이스만 필터링해서 만든 데이터로 거래 단위가 10kg인 케이스만 필터링하여 date 변수로 그룹으로 하는 일평균 1kg당 가격의 변수 price가 만들어진 dpri_SO_SG 데이터를 생성하였다. date2는 YYYYMMDD 형태인 날짜를 YYYY-MM-DD``(%Y-%m-%d) 형태의 날짜로 변환한 변수이고, mmdd 변수는 연도를 제외한 월,일이 MMDD 형태로 만들어진 변수, month_day 변수는 연도를 제외한 월, 일이 MM-DD 형태로 만들어진 변수이다. damt_SO_GR 데이터는 raw 데이터의 price_per_kg 변수 대신 weight 변수의 일별 총합을 date 그룹별로 구해서 amt_kton 변수를 만든 데이터이다. 일별 반입중량의 합을 1,000,000으로 나누어서 kg 단위를 kton 단위로 변환하였다.
date0 <- 20180613
date0l1y <- date0 - 10000
date0l2y <- date0 - 20000
date0l3y <- date0 - 30000
dat_SO_GR <- dat %>% filter(market=='서울가락도매시장')
dpri_SO_GR <- dat_SO_GR %>% filter(unit=='kg',prut==10) %>% group_by(date) %>% summarise(price=round(mean(price_per_kg,na.rm=T),1))
dpri_SO_GR <- dpri_SO_GR %>% mutate(date2=as.Date(as.character(date),format="%Y%m%d"),
mmdd = strftime(as.Date(as.character(date),format="%Y%m%d"), format="%m%d"),
month_day = strftime(as.Date(as.character(date),format="%Y%m%d"), format="%m-%d"),
year = substr(date,1,4))
damt_SO_GR <- dat_SO_GR %>% filter(unit=='kg',prut==10)%>% group_by(date) %>% summarise(amt_kton=round(sum(weight,na.rm=T)/1000000,3))
damt_SO_GR <- damt_SO_GR %>% mutate(date2=as.Date(as.character(date),format="%Y%m%d"),
mmdd = strftime(as.Date(as.character(date),format="%Y%m%d"), format="%m%d"),
month_day = strftime(as.Date(as.character(date),format="%Y%m%d"), format="%m-%d"),
year = substr(date,1,4))올해를 의미하는 2018년을 기준으로 올해 30일 전 l0yb30, 1,2,3년전의 30일 전 l1yb30, l2yb30, l2yb30, 1,2,3년 전의 30일후 l1ya30, l2ya30, l2ya30를 지칭하는 YYYYMMDD 형태의 변수를 생성한 후 오늘 날짜부터 30일 전까지 dpri_SO_GR를 필터랑한 데이터 dpri_l0y 1,2,3년 전의 오늘날짜 30일 전부터 30일 후까지의 dpri_SO_GR을 필터링한 dpri_l1y, dpri_l2y, dpri_l3y 데이터를 생성하였다.
각 연도별 데이터 생성하여 merge() 함수로 변수를 추가하였다.
year0 <- 2018
l0yb30 <- strftime(as.Date(as.character(date0),format="%Y%m%d") - 30, format="%Y%m%d") #30일전
l1yb30 <- strftime(as.Date(as.character(date0l1y),format="%Y%m%d") - 30, format="%Y%m%d") #1년 30일전
l2yb30 <- strftime(as.Date(as.character(date0l2y),format="%Y%m%d") - 30, format="%Y%m%d") #2년 30일전
l3yb30 <- strftime(as.Date(as.character(date0l3y),format="%Y%m%d") - 30, format="%Y%m%d") #3년 30일전
l1ya30 <- strftime(as.Date(as.character(date0l1y),format="%Y%m%d") + 30, format="%Y%m%d") #1년 30일후
l2ya30 <- strftime(as.Date(as.character(date0l2y),format="%Y%m%d") + 30, format="%Y%m%d") #2년 30일후
l3ya30 <- strftime(as.Date(as.character(date0l3y),format="%Y%m%d") + 30, format="%Y%m%d") #3년 30일후
dpri_l0y <- dpri_SO_GR %>% filter(date >= l0yb30, date <= date0)
dpri_l1y <- dpri_SO_GR %>% filter(date >= l1yb30, date <= l1ya30)
dpri_l2y <- dpri_SO_GR %>% filter(date >= l2yb30, date <= l2ya30)
dpri_l3y <- dpri_SO_GR %>% filter(date >= l3yb30, date <= l3ya30) 다음은 각각 연도별로 필터링된 데이터를 하나의 데이터로 merge하는 코드이다. 오늘 날짜부터 30일 전부터 30일 후까지의 MM-DD 형태의 날짜 리스트를 date_list로 생성하고 이 날짜를 기준으로 올해, 1,2,3년 전 일별 가격 데이터를 merge시켜서 dpri_comp 데이터를 만들어준다.
date_list <- data.frame(month_day=strftime(seq(as.Date(l1yb30,format='%Y%m%d'),as.Date(as.character(l1ya30),format='%Y%m%d'),1),format='%m-%d'))
dpri_comp <- merge(date_list,dpri_l0y[,c('month_day','date','date2','mmdd','price')],by='month_day',all.x=T) ; colnames(dpri_comp)[c(2,3,5)] <- c('date_l0','date2_l0','price_l0'); dpri_comp <- dpri_comp[,c(1,4,2,3,5)]
dpri_comp <- merge(dpri_comp,dpri_l1y[,c('month_day','date','date2','price')],by='month_day',all.x=T); colnames(dpri_comp)[6:8] <- c('date_l1','date2_l1','price_l1')
dpri_comp <- merge(dpri_comp,dpri_l2y[,c('month_day','date','date2','price')],by='month_day',all.x=T); colnames(dpri_comp)[9:11] <- c('date_l2','date2_l2','price_l2')
dpri_comp <- merge(dpri_comp,dpri_l3y[,c('month_day','date','date2','price')],by='month_day',all.x=T); colnames(dpri_comp)[12:14] <- c('date_l3','date2_l3','price_l3')
dpri_comp <- dpri_comp[,c('month_day','date2_l0','price_l0','price_l1','price_l2','price_l3')]
colnames(dpri_comp)[2] <- 'date_l0'
dpri_comp <- dpri_comp %>% mutate(date_l0=as.Date(paste(year0,"-",month_day,sep='')))일별 평균 가격 데이터에 결측이 있는 날은 이전의 시점 중 가장 최근 가격이 들어가도록 코드를 짰다. 결측이 하루 이상인 경우에도 이전 시점 가격을 참조할 수 있도록 while() 함수를 사용하였다.
이제 그래프료 표현해보자. 앞선 formattable 패키지 실행과정에서 plotly 패키지를 detach 했기 때문에 다시 library() 함수를 이용해서 plotly 패키지를 로드한 후 아래 코드를 실행해야 한다. 그래프는 차례로 작년과 올해, 2년 전과 올해, 3년전과 올해의 가락시장 일 가격 추세를 비교한다.
gg1.2a <- ggplot() + geom_blank(data=dpri_comp,aes(x=month_day)) +
geom_point(data=dpri_comp[!is.na(dpri_comp$price_l0),c('month_day','price_l0')],aes(x=month_day, y=price_l0, group=NA), color="#4e79a7") +
geom_line(data=dpri_comp[!is.na(dpri_comp$price_l0),c('month_day','price_l0')],aes(x=month_day, y=price_l0, group=NA), color="#4e79a7") +
geom_point(data=dpri_comp[!is.na(dpri_comp$price_l1),c('month_day','price_l1')],aes(x=month_day, y=price_l1, group=NA), color='#f28e2b') +
geom_line(data=dpri_comp[!is.na(dpri_comp$price_l1),c('month_day','price_l1')],aes(x=month_day, y=price_l1, group=NA), color='#f28e2b') +
scale_x_discrete(breaks = as.character(dpri_comp$month_day[c(seq(1,nrow(dpri_comp),5))]), labels = as.character(dpri_comp$month_day[c(seq(1,nrow(dpri_comp),5))])) +
theme_minimal() + scale_color_tableau()
ggplotly(gg1.2a, tooltip = c('x',"y"), height = 400)gg1.2b <- ggplot() + geom_blank(data=dpri_comp,aes(x=month_day)) +
geom_point(data=dpri_comp[!is.na(dpri_comp$price_l0),c('month_day','price_l0')],aes(x=month_day, y=price_l0, group=NA), color="#4e79a7") +
geom_line(data=dpri_comp[!is.na(dpri_comp$price_l0),c('month_day','price_l0')],aes(x=month_day, y=price_l0, group=NA), color="#4e79a7") +
geom_point(data=dpri_comp[!is.na(dpri_comp$price_l2),c('month_day','price_l2')],aes(x=month_day, y=price_l2, group=NA), color='#f28e2b') +
geom_line(data=dpri_comp[!is.na(dpri_comp$price_l2),c('month_day','price_l2')],aes(x=month_day, y=price_l2, group=NA), color='#f28e2b') +
scale_x_discrete(breaks = as.character(dpri_comp$month_day[c(seq(1,nrow(dpri_comp),5))]), labels = as.character(dpri_comp$month_day[c(seq(1,nrow(dpri_comp),5))])) +
theme_minimal() + scale_color_tableau()
ggplotly(gg1.2b, tooltip = c('x',"y"), height = 400)gg1.2c <- ggplot() + geom_blank(data=dpri_comp,aes(x=month_day)) +
geom_point(data=dpri_comp[!is.na(dpri_comp$price_l0),c('month_day','price_l0')],aes(x=month_day, y=price_l0, group=NA), color="#4e79a7") +
geom_line(data=dpri_comp[!is.na(dpri_comp$price_l0),c('month_day','price_l0')],aes(x=month_day, y=price_l0, group=NA), color="#4e79a7") +
geom_point(data=dpri_comp[!is.na(dpri_comp$price_l3),c('month_day','price_l3')],aes(x=month_day, y=price_l3, group=NA), color='#f28e2b') +
geom_line(data=dpri_comp[!is.na(dpri_comp$price_l3),c('month_day','price_l3')],aes(x=month_day, y=price_l3, group=NA), color='#f28e2b') +
scale_x_discrete(breaks = as.character(dpri_comp$month_day[c(seq(1,nrow(dpri_comp),5))]), labels = as.character(dpri_comp$month_day[c(seq(1,nrow(dpri_comp),5))])) +
theme_minimal() + scale_color_tableau()
ggplotly(gg1.2c, tooltip = c('x',"y"), height = 400)dpri_comp 데이터 생성 과정과 유사하게 올해, 1,2,3년전 60일간의 데이터 생성하여 merge() 함수로 하나의 데이터로 변수들을 합쳤다.
damt_l0y <- damt_SO_GR %>% filter(date >= l0yb30, date <= date0)
damt_l1y2 <- damt_SO_GR %>% filter(date >= l1yb30, date <= l1ya30)
damt_l2y2 <- damt_SO_GR %>% filter(date >= l2yb30, date <= l2ya30)
damt_l3y2 <- damt_SO_GR %>% filter(date >= l3yb30, date <= l3ya30)
date_list <- data.frame(month_day=strftime(seq(as.Date(l1yb30,format='%Y%m%d'),as.Date(as.character(l1ya30),format='%Y%m%d'),1),format='%m-%d'))
damt_merg <- merge(date_list,damt_l0y[,c('month_day','date','date2','mmdd','amt_kton')],by='month_day',all.x=T); colnames(damt_merg)[c(2,3,5)] <- c('date_l0','date2_l0','amt_kton_l0'); damt_merg <- damt_merg[,c(1,4,2,3,5)]
damt_merg <- merge(damt_merg,damt_l1y2[,c('month_day','date','date2','amt_kton')],by='month_day',all.x=T); colnames(damt_merg)[6:8] <- c('date_l1','date2_l1','amt_kton_l1')
damt_merg <- merge(damt_merg,damt_l2y2[,c('month_day','date','date2','amt_kton')],by='month_day',all.x=T); colnames(damt_merg)[9:11] <- c('date_l2','date2_l2','amt_kton_l2')
damt_merg <- merge(damt_merg,damt_l3y2[,c('month_day','date','date2','amt_kton')],by='month_day',all.x=T); colnames(damt_merg)[12:14] <- c('date_l3','date2_l3','amt_kton_l3')
damt_comp <- damt_merg[,c('month_day','date2_l0','amt_kton_l0','amt_kton_l1','amt_kton_l2','amt_kton_l3')]
colnames(damt_comp)[2] <- 'date_l0'
damt_comp <- damt_comp %>% mutate(date_l0=as.Date(paste(year0,"-",month_day,sep='')))damt_com 데이터의 경우 결측이 있는 날은 거래가 없었던 날이기 때문에 반입량이 0이 되면 된다.
damt_comp <- damt_comp %>% mutate(amt_kton_l0 = ifelse(date_l0 < date_today,ifelse(is.na(amt_kton_l0),0,amt_kton_l0),amt_kton_l0))
damt_comp[,c('amt_kton_l1','amt_kton_l2','amt_kton_l3')] <- apply(damt_comp[,c('amt_kton_l1','amt_kton_l2','amt_kton_l3')], 2, FUN=function(x) ifelse(is.na(x),0,x)) 그래프는 차례로 작년과 올해, 2년 전과 올해, 3년전과 올해의 가락시장 일 반입량 추세를 비교한다.
gg1.2aa <- ggplot() + geom_blank(data=damt_comp,aes(x=month_day)) +
geom_point(data=damt_comp[!is.na(damt_comp$amt_kton_l0),c('month_day','amt_kton_l0')],aes(x=month_day, y=amt_kton_l0, group=NA), color="#4e79a7") +
geom_line(data=damt_comp[!is.na(damt_comp$amt_kton_l0),c('month_day','amt_kton_l0')],aes(x=month_day, y=amt_kton_l0, group=NA), color="#4e79a7") +
geom_point(data=damt_comp[!is.na(damt_comp$amt_kton_l1),c('month_day','amt_kton_l1')], aes(x=month_day, y=amt_kton_l1), color='#f28e2b') +
geom_line(data=damt_comp[!is.na(damt_comp$amt_kton_l1),c('month_day','amt_kton_l1')], aes(x=month_day, y=amt_kton_l1, group=NA), color='#f28e2b') +
geom_area(data=damt_comp[!is.na(damt_comp$amt_kton_l0),c('month_day','amt_kton_l0')], aes(x=month_day, y=amt_kton_l0, group=NA), fill='#4e79a7', alpha=0.2) +
geom_area(data=damt_comp[!is.na(damt_comp$amt_kton_l1),c('month_day','amt_kton_l1')], aes(x=month_day, y=amt_kton_l1, group=NA), fill='#f28e2b', alpha=0.2) +
labs(x = 'month-day', y = 'amt_kton') +
scale_x_discrete(breaks = as.character(damt_comp$month_day[c(seq(1,nrow(damt_comp),5))]), labels = as.character(damt_comp$month_day[c(seq(1,nrow(damt_comp),5))])) +
theme_minimal() + scale_color_tableau()
ggplotly(gg1.2aa, tooltip = c("x", "y"), height=400)gg1.2bb <- ggplot() + geom_blank(data=damt_comp,aes(x=month_day)) +
geom_point(data=damt_comp[!is.na(damt_comp$amt_kton_l0),c('month_day','amt_kton_l0')],aes(x=month_day, y=amt_kton_l0, group=NA), color="#4e79a7") +
geom_line(data=damt_comp[!is.na(damt_comp$amt_kton_l0),c('month_day','amt_kton_l0')],aes(x=month_day, y=amt_kton_l0, group=NA), color="#4e79a7") +
geom_point(data=damt_comp[!is.na(damt_comp$amt_kton_l2),c('month_day','amt_kton_l2')], aes(x=month_day, y=amt_kton_l2), color='#f28e2b') +
geom_line(data=damt_comp[!is.na(damt_comp$amt_kton_l2),c('month_day','amt_kton_l2')], aes(x=month_day, y=amt_kton_l2, group=NA), color='#f28e2b') +
geom_area(data=damt_comp[!is.na(damt_comp$amt_kton_l0),c('month_day','amt_kton_l0')], aes(x=month_day, y=amt_kton_l0, group=NA), fill='#4e79a7', alpha=0.2) +
geom_area(data=damt_comp[!is.na(damt_comp$amt_kton_l2),c('month_day','amt_kton_l2')], aes(x=month_day, y=amt_kton_l2, group=NA), fill='#f28e2b', alpha=0.2) +
labs(x = 'month-day', y = 'amt_kton') +
scale_x_discrete(breaks = as.character(damt_comp$month_day[c(seq(1,nrow(damt_comp),5))]), labels = as.character(damt_comp$month_day[c(seq(1,nrow(damt_comp),5))])) +
theme_minimal() + scale_color_tableau()
ggplotly(gg1.2bb, tooltip = c("x", "y"), height=400)gg1.2cc <- ggplot() + geom_blank(data=damt_comp,aes(x=month_day)) +
geom_point(data=damt_comp[!is.na(damt_comp$amt_kton_l0),c('month_day','amt_kton_l0')],aes(x=month_day, y=amt_kton_l0, group=NA), color="#4e79a7") +
geom_line(data=damt_comp[!is.na(damt_comp$amt_kton_l0),c('month_day','amt_kton_l0')],aes(x=month_day, y=amt_kton_l0, group=NA), color="#4e79a7") +
geom_point(data=damt_comp[!is.na(damt_comp$amt_kton_l3),c('month_day','amt_kton_l3')], aes(x=month_day, y=amt_kton_l3), color='#f28e2b') +
geom_line(data=damt_comp[!is.na(damt_comp$amt_kton_l3),c('month_day','amt_kton_l3')], aes(x=month_day, y=amt_kton_l3, group=NA), color='#f28e2b') +
geom_area(data=damt_comp[!is.na(damt_comp$amt_kton_l0),c('month_day','amt_kton_l0')], aes(x=month_day, y=amt_kton_l0, group=NA), fill='#4e79a7', alpha=0.2) +
geom_area(data=damt_comp[!is.na(damt_comp$amt_kton_l3),c('month_day','amt_kton_l3')], aes(x=month_day, y=amt_kton_l3, group=NA), fill='#f28e2b', alpha=0.2) +
labs(x = 'month-day', y = 'amt_kton') +
scale_x_discrete(breaks = as.character(damt_comp$month_day[c(seq(1,nrow(damt_comp),5))]), labels = as.character(damt_comp$month_day[c(seq(1,nrow(damt_comp),5))])) +
theme_minimal() + scale_color_tableau()
ggplotly(gg1.2cc, tooltip = c("x", "y"), height=400)factor_pred <- data.frame(factors=c('가격패턴','반입량패턴', '계절적요인', '기상요인', '기타'),imp_past=c(1,2,3,4,5),imp_future=c(5,3,4,2,1))
plot_ly(type = 'scatterpolar', fill = 'toself') %>% add_trace(r = factor_pred$imp_past, theta = factor_pred$factors, name = '최근7일') %>%
add_trace(r = factor_pred$imp_future, theta = factor_pred$factors, name = '향후3일') %>%
layout(polar = list(radialaxis = list(visible = T,range = c(0,5))))## No scatterpolar mode specifed:
## Setting the mode to markers
## Read more about this attribute -> https://plot.ly/r/reference/#scatter-mode
## No scatterpolar mode specifed:
## Setting the mode to markers
## Read more about this attribute -> https://plot.ly/r/reference/#scatter-mode
## No scatterpolar mode specifed:
## Setting the mode to markers
## Read more about this attribute -> https://plot.ly/r/reference/#scatter-modeunit_list <- factor(c('4kg상자','8kg그물망','10kg그물망','10kg상자','12kg그물망','20kg상자'))
unit_df <- data.frame(unit_merg=unit_list)
tab_date <- data.frame(date=rep(NA,10))
cnt <- 1
# i <- 0
for(i in 0:9) {
tmp <- dat %>% filter(date==as.numeric(strftime(as.Date(as.character(date0),format="%Y%m%d") - i, format="%Y%m%d")), unit_merg%in%unit_list) %>% group_by(unit_merg) %>% summarize(qty=sum(qty,na.rm=T),price=round(mean(price_per_kg,na.rm=T),1))
if(nrow(tmp)>2) {
if(i == 0) {
pri_dist <- merge(unit_df,tmp,by='unit_merg',all.x=T)
} else {
pri_dist <- merge(pri_dist,tmp,by='unit_merg',all.x=T)
}
colnames(pri_dist)[c((ncol(pri_dist)-1),ncol(pri_dist))] <- c(paste('qty_l',cnt,'d',sep=''),paste('price_l',cnt,'d',sep=''))
tab_date[cnt,1] <- as.character(as.Date(as.character(date0),format="%Y%m%d") - i)
cnt <- cnt + 1
}
}
colnames(pri_dist)[1] <- 'unit_name'
pri_dist <- pri_dist[c(5,6,1:4),]
pri_dist <- pri_dist[,1:11]
pri_dist$na_cnt <- apply(pri_dist,1,function(x) sum(is.na(x)))
pri_dist <- pri_dist[pri_dist$na_cnt!=10,]gg1.4a <- ggplot(data=pri_dist,aes(x=ordered(unit_name, levels=pri_dist[,'unit_name']),y=price_l1d)) + geom_bar(stat='identity',fill="#A63603", width=0.6) + xlab(tab_date[1,2]) + coord_cartesian(ylim = c(0, 1000))
gg1.4b <- ggplot(data=pri_dist,aes(x=ordered(unit_name, levels=pri_dist[,'unit_name']),y=price_l2d)) + geom_bar(stat='identity',fill="#D94801", width=0.6) + xlab(tab_date[1,2]) + coord_cartesian(ylim = c(0, 1000))
gg1.4c <- ggplot(data=pri_dist,aes(x=ordered(unit_name, levels=pri_dist[,'unit_name']),y=price_l3d)) + geom_bar(stat='identity',fill="#F16913", width=0.6) + xlab(tab_date[1,3]) + coord_cartesian(ylim = c(0, 1000))
gg1.4d <- ggplot(data=pri_dist,aes(x=ordered(unit_name, levels=pri_dist[,'unit_name']),y=price_l4d)) + geom_bar(stat='identity',fill="#FD8D3C", width=0.6) + xlab(tab_date[1,4]) + coord_cartesian(ylim = c(0, 1000))
gg1.4e <- ggplot(data=pri_dist,aes(x=ordered(unit_name, levels=pri_dist[,'unit_name']),y=price_l5d)) + geom_bar(stat='identity',fill="#FDAE6B", width=0.6) + xlab(tab_date[1,5]) + coord_cartesian(ylim = c(0, 1000))
subplot(ggplotly(gg1.4a,tooltip = c("x", "y")),ggplotly(gg1.4b,tooltip = c("x", "y")),ggplotly(gg1.4c,tooltip = c("x", "y")),ggplotly(gg1.4d,tooltip = c("x", "y")),ggplotly(gg1.4e,tooltip = c("x", "y")), margin = 0.05, nrows=5) 